AI-assisted vs manual systematic review screening: evidence, workflows, and limits
Compare manual dual screening with AI-assisted triage using PRISMA 2020 and Cochrane study-selection guidance, plus honest notes on how Study Screener implements each path.
Scope. This article compares title and abstract screening—not full-text PDF review, data extraction, or risk-of-bias assessment. Timing examples below are illustrative unless you measure them in your own pilot.
Disclosure. Study Screener offers manual collaborative screening and a separate AI-assisted batch classifier. We describe both honestly, including where our AI path differs from tools that re-rank records while you screen.
Two different questions
Researchers often conflate three ideas:
- Manual dual screening — two people independently code include/exclude (or maybe) against a protocol; disagreements are resolved. This remains the norm in Cochrane-style reviews and PRISMA reporting (Cochrane Handbook, Ch. 4; PRISMA 2020).
- Prioritization while you screen — software surfaces likely relevant records earlier in the queue; efficiency depends on your stopping rule and how much of the set you still review.
- LLM batch classification — each record is scored against written criteria in one pass (as in Study Screener’s AI screening jobs). Throughput can be high, but recall depends on criteria quality, model behavior, and your validation plan—not on efficiency metrics from a different type of tool.
Confusing (2) and (3) is how unsupported “95% sensitivity” claims appear in marketing. The comparison below treats manual dual review and batch AI triage as separate workflows you document under PRISMA 2020 study-selection reporting.
Manual screening: what “good” looks like
Typical workflow (PRISMA-aligned)
- Register protocol and eligibility criteria.
- Search databases; merge and deduplicate outside the screening tool (Study Screener does not remove duplicates on import today, this feature will be added soon enough).
- Import a single cleaned RIS (or PubMed
.txt) file. - Two reviewers screen independently; use blinding so neither sees the other’s vote until both decide (Cochrane Handbook, Ch. 4).
- Resolve conflicts (discussion or third reviewer).
- Export decision logs and included RIS for full-text retrieval and PRISMA counts.
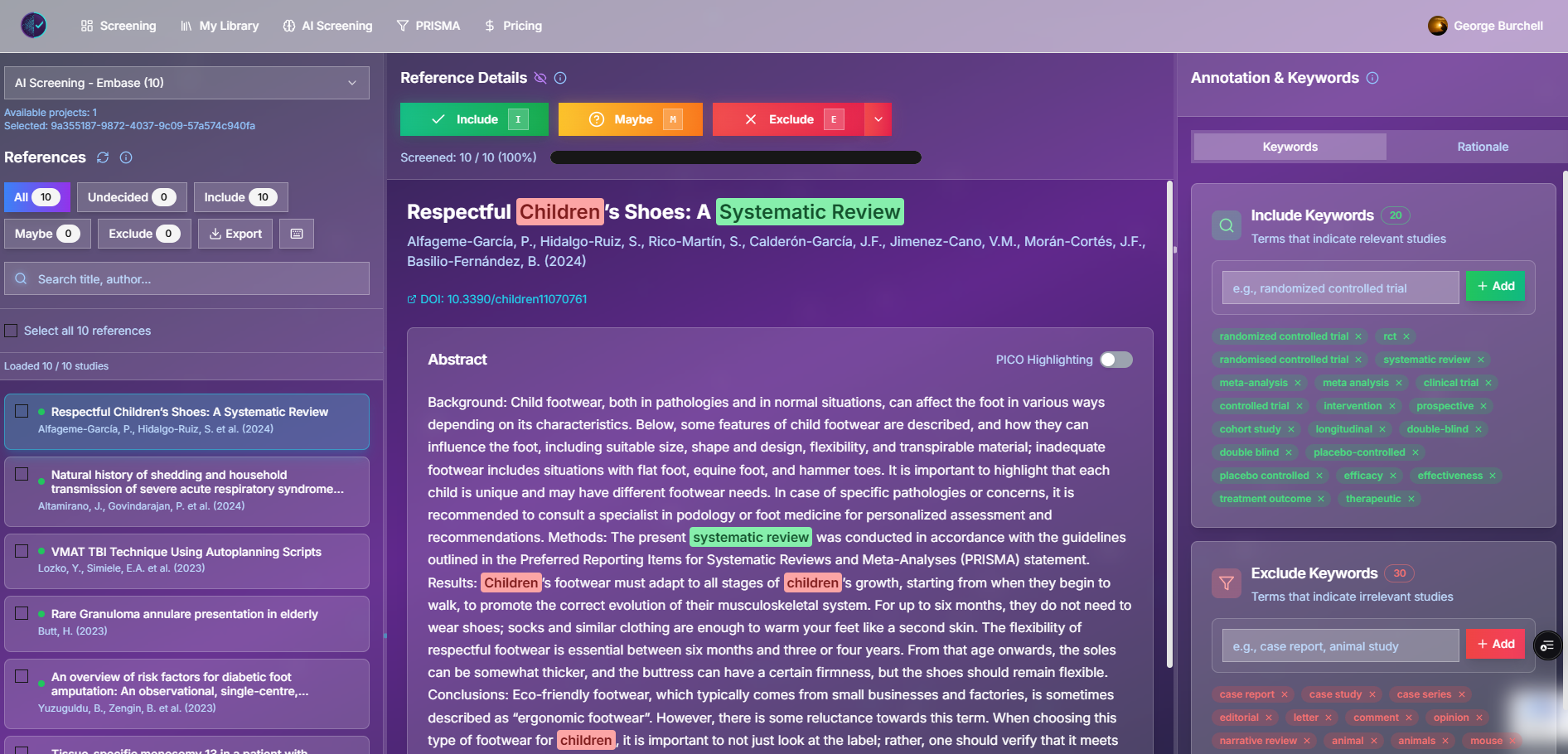
Figure: Manual screening in Study Screener (demo). Keyboard shortcuts: I / M / E.
Time and agreement (realistic ranges, not guarantees)
The Cochrane Handbook does not give a single “hours per 10,000 records” figure because speed depends on topic difficulty, abstract quality, and team experience. Useful anchors:
| Source | What it implies |
|---|---|
| Practitioner guides (e.g. our beginner screening guide) | Roughly 100–300 title/abstract decisions per hour per experienced reviewer after calibration—not on day one. |
| Dual screening multiplier | Two blinded reviewers ≈ 2× person-time before conflict resolution. |
| Inter-rater agreement | Report kappa or percent agreement on a pilot sample; Cochrane expects documented resolution of disagreements. Treat any κ value as study-specific, not universal. |
Illustrative arithmetic (not a handbook figure): 10,000 records × ~20 seconds each ≈ 55 person-hours per reviewer; dual screening ≈ 110 person-hours before conflicts. Use your pilot median seconds per decision instead.
Strengths and failure modes
| Strength | Failure mode |
|---|---|
| Transparent to auditors and journals | Fatigue and drift on large sets |
| Handles nuanced criteria when trained | Vague criteria → endless “maybe” |
| No model version to document | Slow at scale without prioritization |
AI-assisted screening: concepts without over-claiming
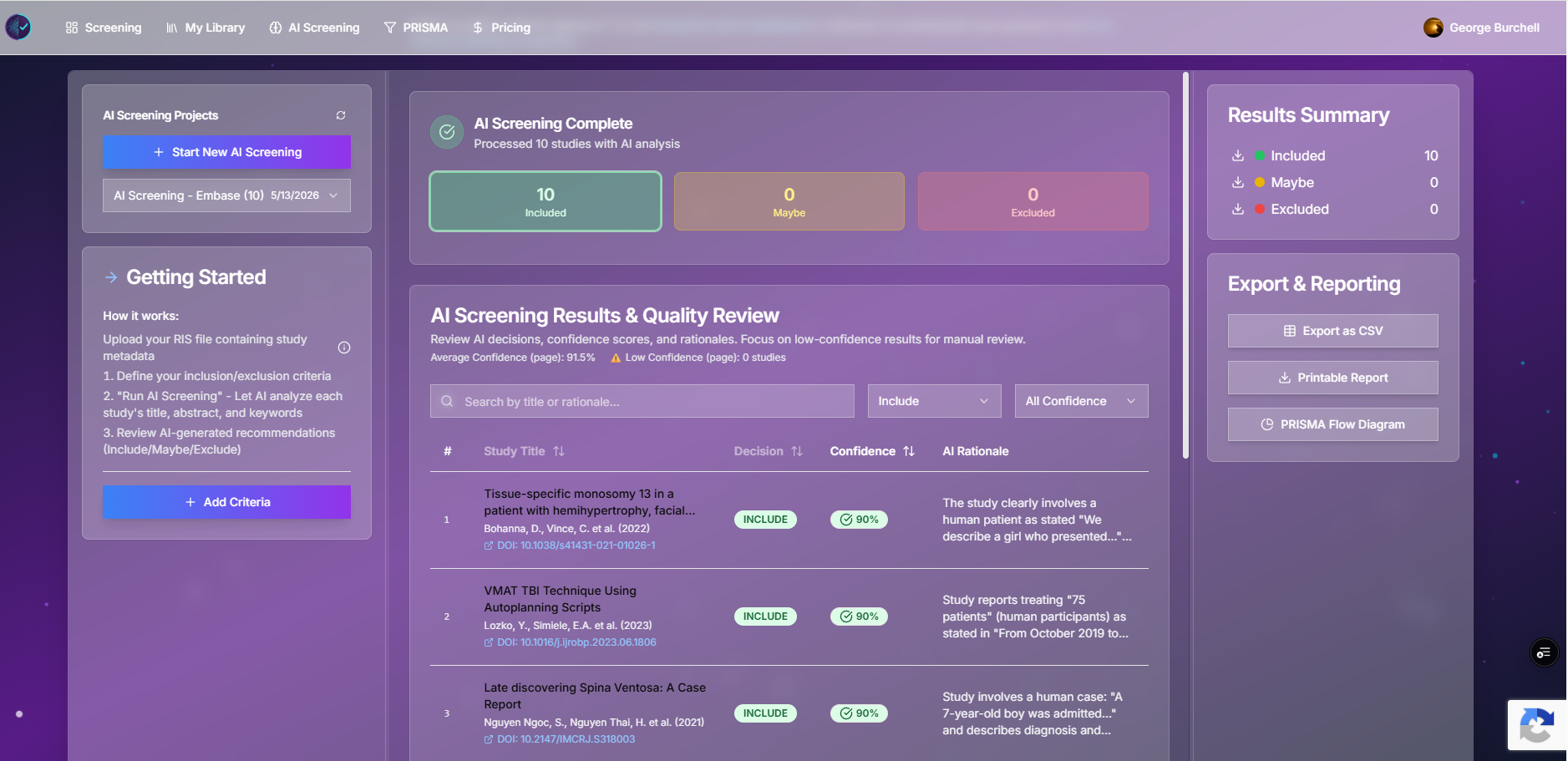
Some tools help you screen fewer records early by ranking likely includes. Others, including Study Screener’s AI screening, run a batch pass over the full set:
- You upload RIS/TXT and enter inclusion, exclusion, and research question text.
- The backend classifies each record (include / exclude / maybe) with confidence and rationale per row.
- Results export to CSV/RIS; PRISMA modal can pull job aggregates (duplicate removal in that export is still simplified—enter dedupe counts manually when needed).
Figure: AI screening workspace. Treat outputs as triage suggestions until you validate against your protocol.
We do not publish independent sensitivity benchmarks for this LLM classifier yet (see our docs performance note). Plan a validation sample (e.g. 200–400 records double-screened manually) before trusting auto-excludes on a final review. PRISMA 2020 expects transparent reporting of how studies were identified and selected—document any AI step, criteria, and human checks in your methods.
Side-by-side: manual vs AI-assisted (conceptual)
| Dimension | Manual dual screening (Study Screener) | AI-assisted batch (Study Screener) |
|---|---|---|
| Primary output | Per-reviewer decisions + audit trail | Per-record AI label + confidence |
| Efficiency evidence | Team throughput (pilot timing) | Your validation study; job runtime |
| Recall risk | Reviewer fatigue, criteria drift | Model + prompt + criteria ambiguity |
| PRISMA reporting | Standard dual-review narrative (PRISMA 2020) | Document tool, criteria, validation, overrides |
| In one combined project? | No — manual and AI jobs are separate pipelines today; bridge via exports if needed | Same |
Worked example A — manual dual screening (small RCT review)
Setup (fictional but realistic): 3,200 records after deduplication; two reviewers; blinded screening in Study Screener.
| Step | Action | Note |
|---|---|---|
| 1 | Pilot n = 80 independently | Calculate agreement; rewrite 2–3 criteria bullets |
| 2 | Screen blinded; use Maybe for borderline | PRISMA “other reasons” minimized if you resolve maybes before full text |
| 3 | Owner unblinds or auto-unblind when both finish | Conflicts visible in library / team views |
| 4 | Third reviewer resolves disagreement cases | Log resolution in decision notes |
| 5 | Export included RIS + decision CSV | Full-text stage outside app |
Reporting sentence (methods): “Two reviewers independently screened titles and abstracts in Study Screener with blinding; conflicts were resolved by [consensus / third reviewer], consistent with Cochrane Handbook, Ch. 4 and PRISMA 2020 study-selection reporting.”
Worked example B — AI triage + manual validation (large scoping review)
Setup: 18,000 records; tight deadline; AI job for first-pass triage only.
| Step | Action | Why |
|---|---|---|
| 1 | Run AI on written PICO-style criteria | Forces explicit rules the model can apply |
| 2 | Export low-confidence and maybe sets | Highest risk of false negatives |
| 3 | Manually dual-screen a random 5–10% of AI excludes | Estimate missed includes; adjust thresholds |
| 4 | Manually screen all AI includes (or dual-screen includes + borderline) | Protects precision for downstream full text |
| 5 | PRISMA diagram | Use diagram builder or AI job PRISMA export; manually enter dedupe counts |
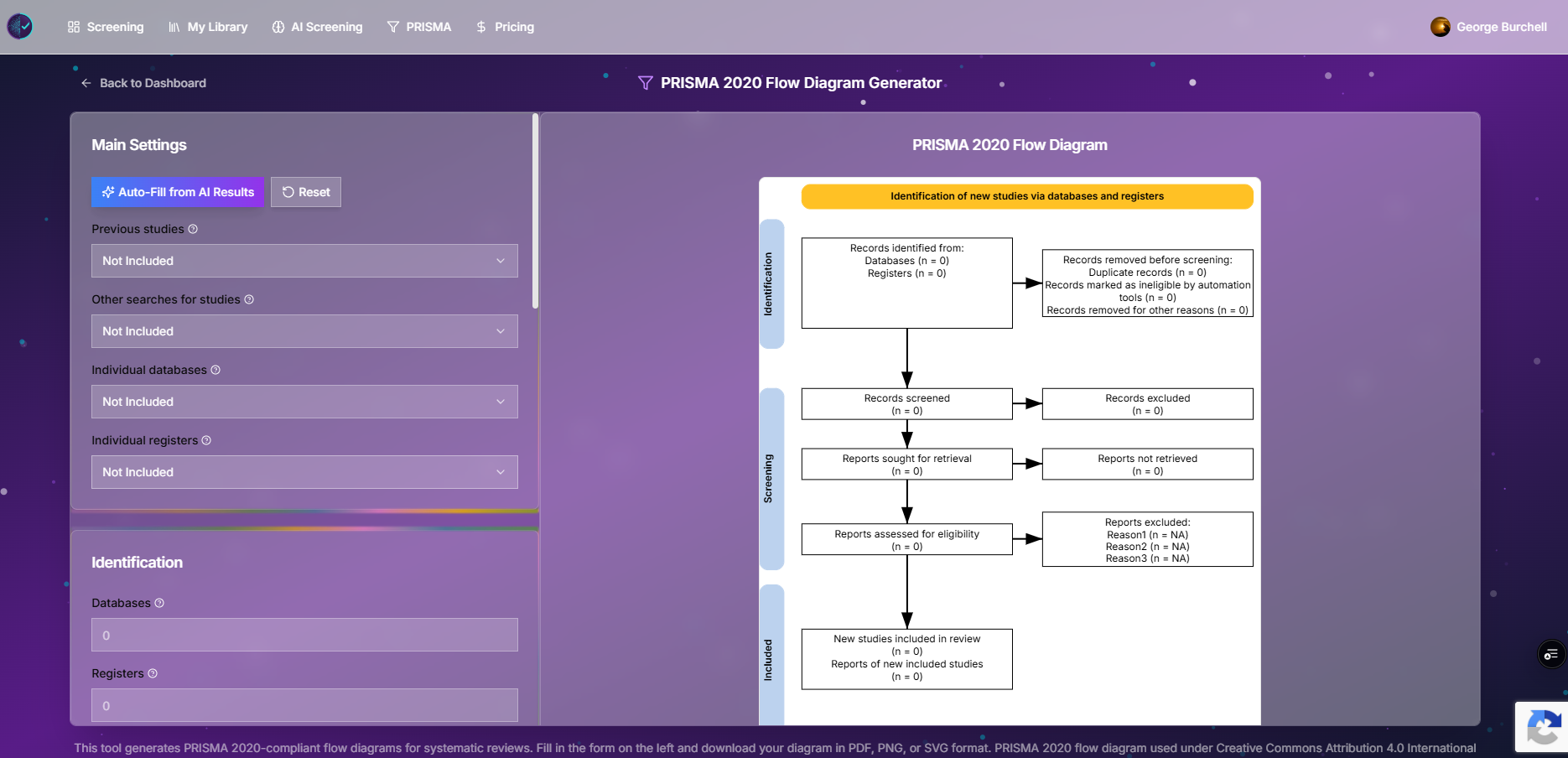
Figure: Standalone PRISMA 2020 builder—use when AI auto-fill does not match your dedupe log.
Reporting sentence (methods): “We used LLM-assisted title/abstract triage (Study Screener, model version [X], date), then dual human review on [includes + sample of excludes], per PRISMA 2020 study-selection guidance. We report [validation sample size] and any protocol deviations.”
Governance checklist before you rely on AI excludes
- Protocol pre-specifies whether AI is used and for which stage
- Criteria are binary/testable where possible (misconception post)
- Validation sample size justified (pilot κ + false-negative spot checks)
- Low-confidence policy written (always human-review?)
- Exports archived (CSV decision log, model/job IDs if available)
- PRISMA counts match dedupe log (not only tool defaults)
- Journal/regulator accepts AI-assisted selection for your field (check target journal)
When manual-only is enough
- Small corpora (< ~500 records) where setup time dominates gains.
- Criteria require full-text judgment at title stage (rare but protocol-specific).
- You cannot document AI validation to journal standards.
When AI-assisted triage is worth testing
- > ~2,000 records with stable criteria.
- You can budget human time to validate excludes.
- You separate triage (AI) from final inclusion (humans).
Study Screener paths (verified product behavior)
| Path | URL | Notes |
|---|---|---|
| Manual screening | /screening, demo | Blinding on by default; exports RIS/CSV per reviewer decisions |
| AI screening | /ai-screening | Credit-based; separate from manual project records |
| PRISMA | /prisma-diagram | Manual counts; AI modal uses job stats |
Plan limits (current code): free tier 1 owned manual project; AI plan 5 owned projects—see pricing before promising capacity to a consortium.
References
- Page MJ, et al. PRISMA 2020 statement. BMJ 2021. https://doi.org/10.1136/bmj.n71
- Cochrane Handbook, Chapter 4 — Study selection. https://training.cochrane.org/handbook/current/chapter-04
Related reading
Educational note: Always report what you validated on your dataset. PRISMA 2020 and the Cochrane Handbook are the authoritative sources for study-selection methods—not vendor efficiency claims.
